Si tuviéramos que definir la «privacidad diferencial«, podríamos decir que se trata de un conjunto de sistemas y prácticas que permiten extraer conclusiones sobre un grupo que, en todo momento, mantiene privados los datos de cada uno de sus miembros.
La privacidad diferencial no es un algoritmo. Es un sistema o marco de trabajo para mejorar la privacidad de los datos. Este sistema estadístico permite recolectar datos y analizarlos sin que ello comprometa la identidad y la privacidad de quienes los proporcionan.
El concepto tiene su origen en un estudio realizado por Microsoft Research, la división de investigación y desarrollo de la compañía en Redmond, y publicado en 2006 por Cynthia Dwork, Frank McSherry, Kobbi Nissim y Adam Smit. En este ámbito, Microsoft ha presentado recientemente la primera plataforma de código abierto del mundo para la privacidad diferencial que funciona bajo la iniciativa OpenDP. Una plataforma que ha sido desarrollada por un equipo de investigadores de la Universidad de Harvard y que está disponible para cualquier persona que quiera usarla para el análisis de datos. En concreto, con WhiteNoise, un paquete de herramientas para privacidad diferencial que ya está disponible en código abierto en GitHub, los desarrolladores experimentan con él, así como a través de Azure Machine Learning.
Cómo funciona la privacidad diferencial
Para entender exactamente cómo funciona la privacidad diferencial, podemos recurrir a un ejemplo. Supongamos que queremos saber la media de dinero que un grupo de personas tiene en su bolsillo para comprar un libro. Al tratarse de un dato sensible, en lugar de formular la pregunta de manera directa, pediremos a las personas que añadan un valor aleatorio (denominado noise, «ruido» en español) entre un rango de -100 y +100 a la cantidad que tienen en su bolsillo y que nos proporcionen la suma resultante. De esta manera, si una persona «A» tiene 30 euros en su bolsillo y esta añade un número, digamos -10, el resultante sería 30 más -10 igual a 20 euros, preservando así la privacidad individual de la persona.
En otras palabras, para proteger la privacidad de los datos obtenidos de diferentes personas añadimos ruido (un número aleatorio, como en el ejemplo anterior) a los datos para hacerlos más privados y seguros. La privacidad diferencial funciona añadiendo ruido estadístico a los datos, bien a los datos iniciales o a los datos de salida.
Pero, ¿cómo de útil serán esos nuevos conjuntos de datos si son todos números aleatorios? Para dar respuesta a esta pregunta tendríamos que adentrarnos en la ley de los grandes números, que básicamente viene a decir que, a medida que crece el tamaño de una muestra, su media se acerca al promedio esperado de toda la población de la muestra.
La privacidad diferencial funciona añadiendo ruido estadístico a los datos, bien a los datos iniciales o a los datos de salida
Es decir, que cuando tenemos un número de personas que nos dan sus datos (incluyendo el ruido), se puede concluir que la media estadística de los datos recolectados se aproxima bastante a la media real si no hubiéramos introducido el ruido. Así pues, al final, siguiendo el ejemplo, obtendremos la media de dinero que tiene, de media, las personas entrevistadas, al mismo tiempo que mantenemos su privacidad. Sin embargo, ¿cómo podemos estar seguros de que la privacidad de una persona en un conjunto de datos está protegida? La respuesta es muy sencilla: si eliminamos a una persona del conjunto de datos y el resultado no varía, entonces la privacidad de esa persona y la de todos estará protegida.
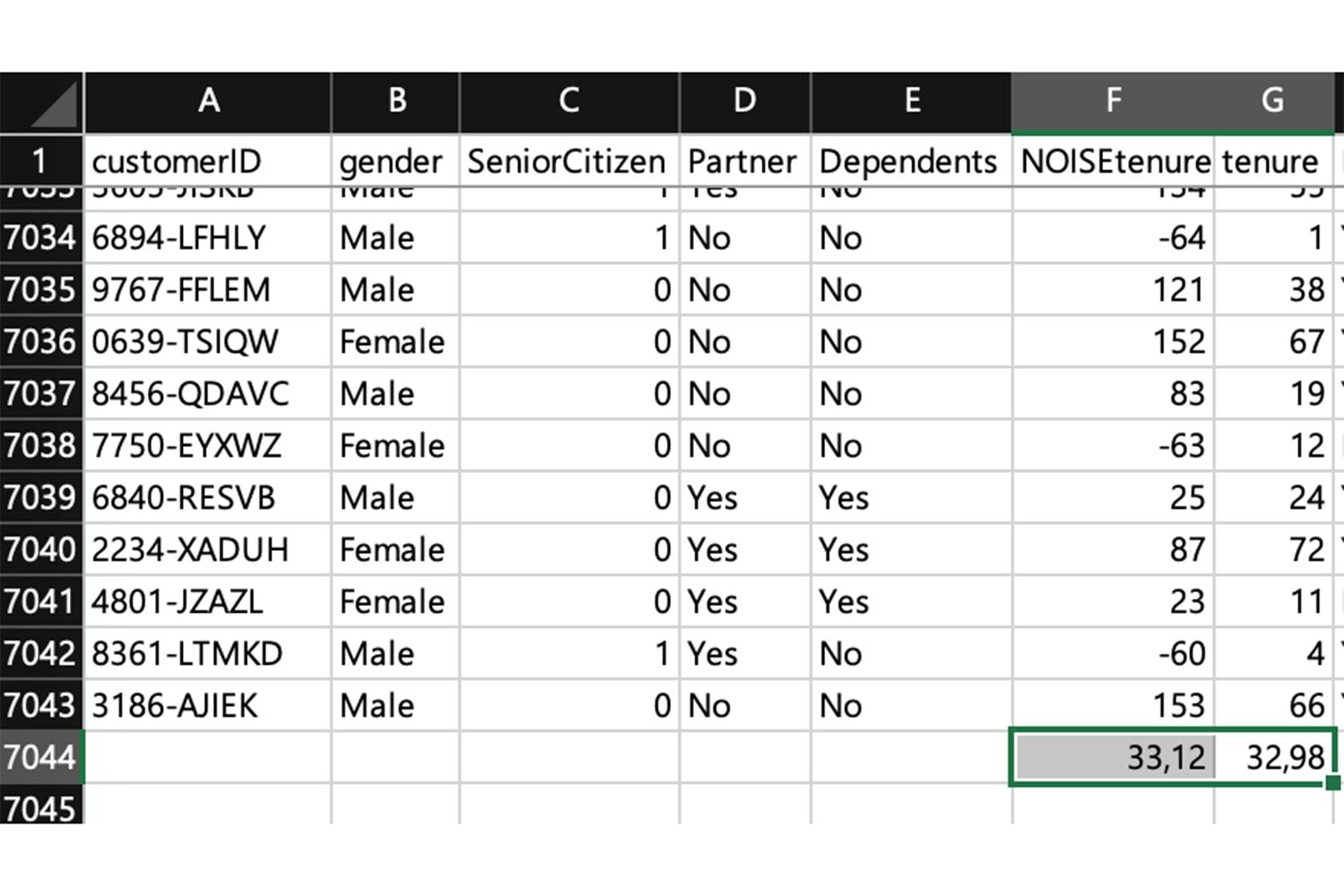
Para comprobarlo, crearemos a continuación un conjunto de datos con N-1 muestras, considerando N el conjunto de datos original. Pongamos de ejemplo un conjunto de datos abiertos de tasas de abandono del sector de las telecomunicaciones descargado de Kaggle. Como podéis apreciar en la tabla, nos hemos centrado en la columna «tenencia» y hemos creado una columna F, añadiendo ruido entre los intervalos -100 y +100 y calculando su promedio, cuyo resultado es 33.
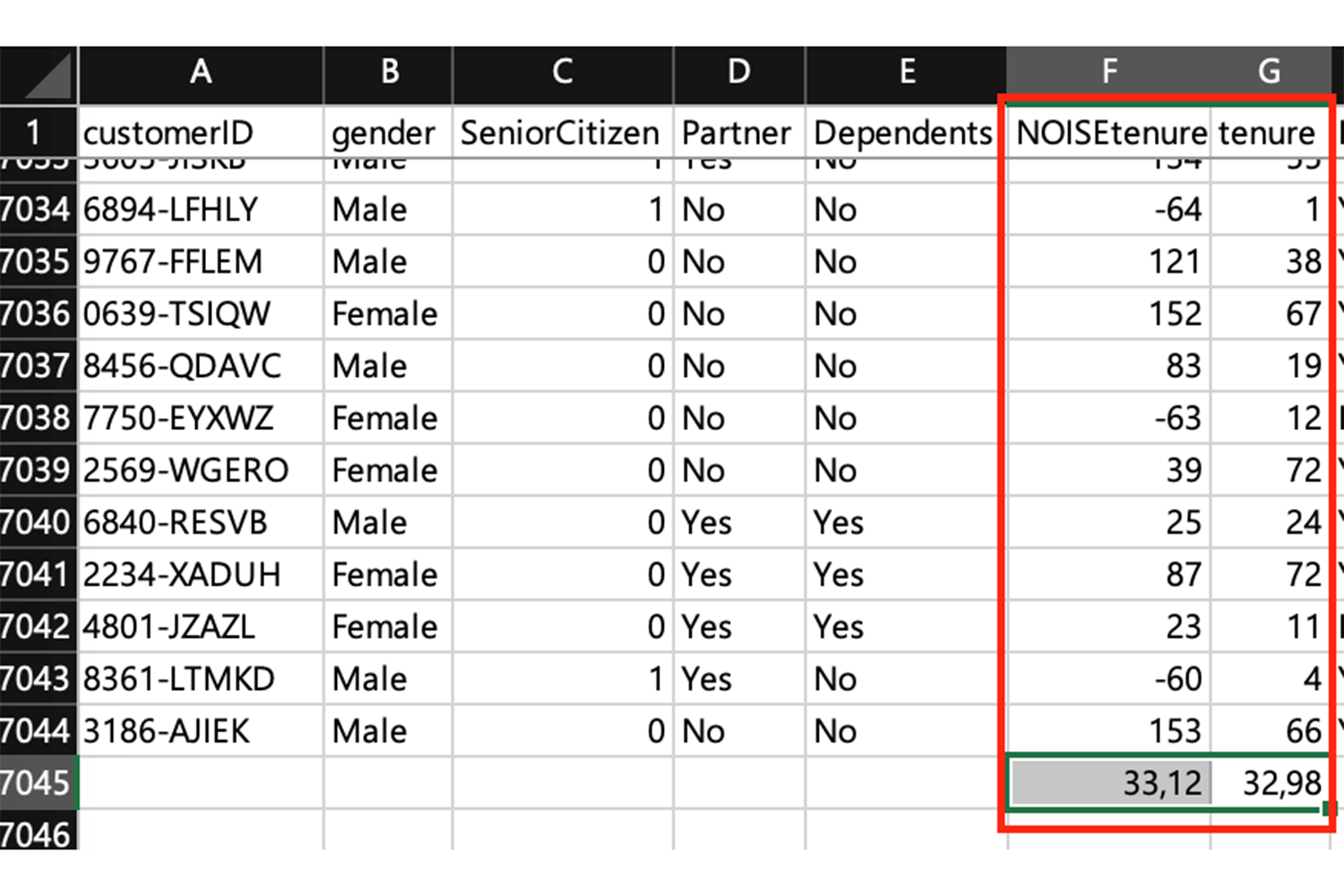
Ahora vamos a ver qué sucede si hacemos el promedio tras eliminar el registro de la persona 2569-WGERO. He mantenido la columna G (la original de tenencia) a efectos de visualizar que los datos varían entre la columna original (G) y la columna con ruido (F); columna esta última que garantiza la privacidad. Como podemos apreciar, el nuevo conjunto de datos N-1 sigue teniendo la misma media que el conjunto original de datos N.
La privacidad diferencial es un marco de trabajo para evaluar las garantías proporcionadas por un mecanismo que ha sido diseñado para proteger la privacidad y resolver muchas de las limitaciones de otras aproximaciones como k-anonymity. La idea es introducir una componente aleatoria en el mecanismo que garantice la privacidad en un algoritmo de aprendizaje (aunque, como hemos visto, se puede aplicar a cualquier escenario).
El objetivo de introducir una aleatoriedad en un algoritmo de aprendizaje es dificultar la identificación de los aspectos conductuales de un modelo definido, ya que los parámetros provienen de la aleatoriedad que hay en los datos de entrenamiento. Sin esta aleatoriedad, podríamos hacernos preguntas del tipo «¿cuáles son los parámetros que escoge el algoritmo de aprendizaje cuando lo entrenamos con un conjunto de datos?» Con la aleatoriedad, la pregunta se convierte en «¿cuál es la probabilidad de que el algoritmo de aprendizaje escoja parámetros dentro de este conjunto de parámetros posibles, cuando lo entrenamos con un conjunto de datos?»
¿Cómo está el mercado?
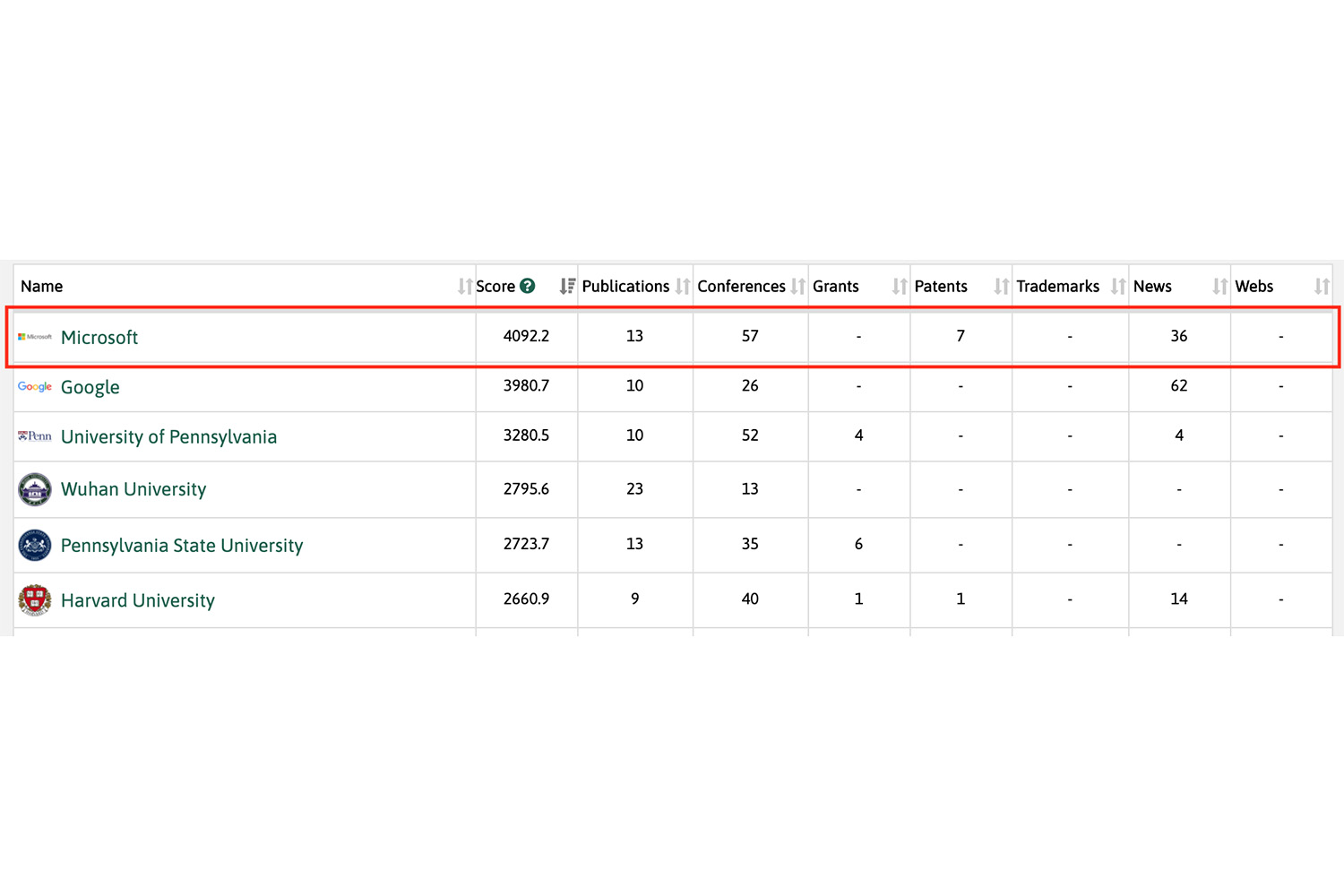
A pesar de que sean muchas las empresas y entidades que están investigando sobre la privacidad diferencial, Microsoft es la que más está invirtiendo, investigando y obteniendo patentes relacionadas con sistemas de respuesta geométrica y algoritmos para preservar la privacidad.
Reto
La última novedad que ha presentado Microsoft junto con el Open Data Institute es el lanzamiento del Reto de Datos Abiertos en la Educación. Este proyecto tiene el objetivo de analizar la relación entre el acceso a la banda ancha y los resultados educativos de estudiantes entre cinco y 18 años. Para ello, los participantes tendrán acceso a los datos de uso de banda ancha estadounidense de Microsoft con privacidad diferencial aplicada.
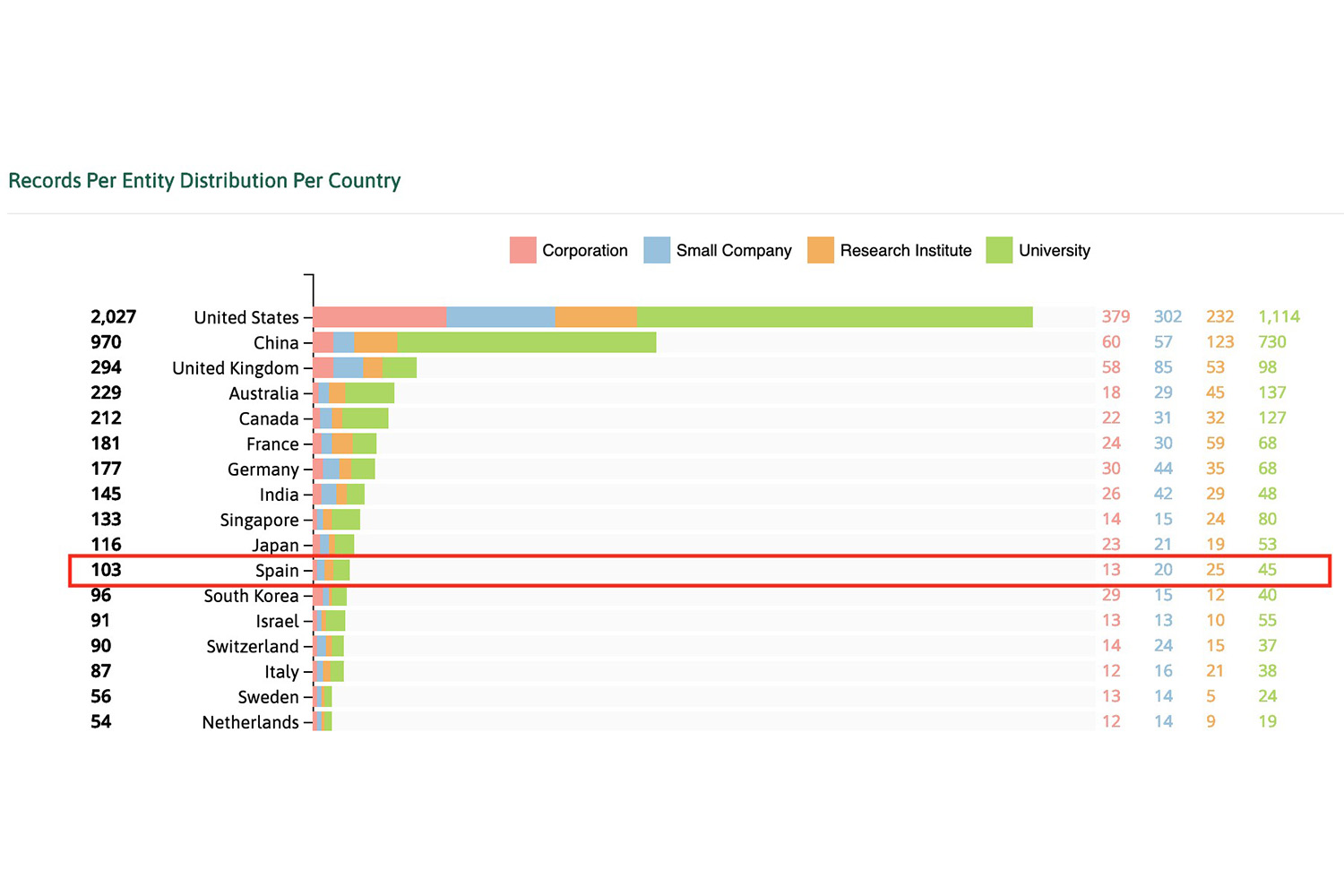
En lo que concierne al ranking de países que investigan sobre privacidad diferencial, podemos afirmar que España está relativamente bien situada, aunque esté muy por debajo de países punteros como Estados Unidos o China.
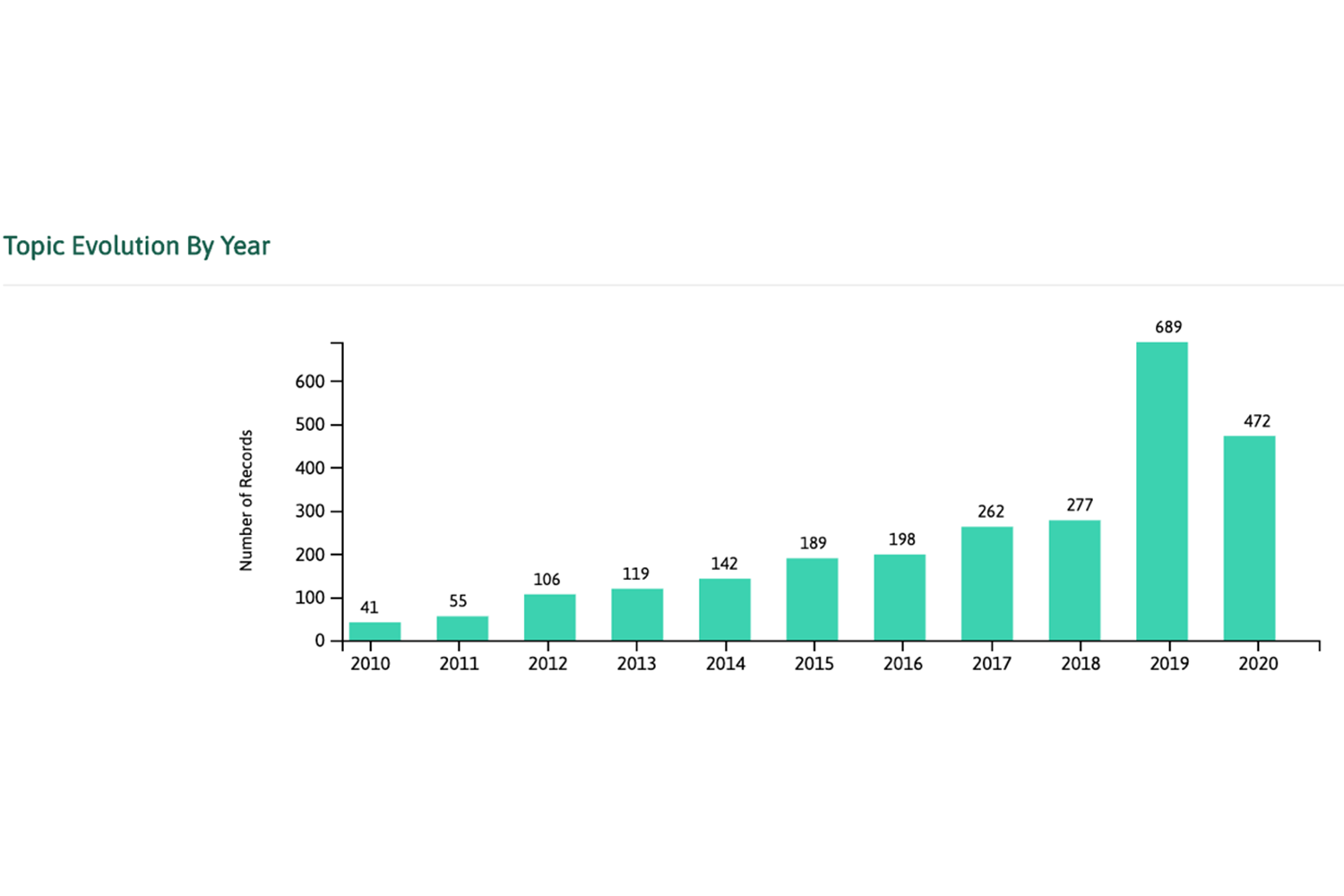
Por último, en este gráfico podemos apreciar el creciente interés en la privacidad diferencial a lo largo de estos últimos años en lo que se refiere a la investigación en privacidad de datos.
Más información
- Visión de Microsoft sobre DP.
- Uso de privacidad diferencial en el puesto de trabajo.
- Uso de WhiteNoise package.
- OpenDP (en colaboración con la Universidad de Harvard).